Running Scala Code in Docker
Sat Feb 13 2021
Alrighty, folks, this blog post is pretty straightforward from the title. We are going to be running Scala code in Docker containers. Specifically, we will be using SBT and docker-compose. SBT is a built tool primarily used by Scala developers, and docker-compose is a tool for defining docker environments.
To start, we need to create a simple Docker container that can build our scala code. From an existing Java JDK container, SBT is straightforward to install from a package manager.
FROM openjdk:8u232
ARG SBT_VERSION=1.4.1
# Install sbt
RUN \
mkdir /working/ && \
cd /working/ && \
curl -L -o sbt-$SBT_VERSION.deb https://dl.bintray.com/sbt/debian/sbt-$SBT_VERSION.deb && \
dpkg -i sbt-$SBT_VERSION.deb && \
rm sbt-$SBT_VERSION.deb && \
apt-get update && \
apt-get install sbt && \
cd && \
rm -r /working/ && \
sbt sbtVersion
RUN mkdir -p /root/build/project
ADD build.sbt /root/build/
ADD ./project/plugins.sbt /root/build/project
RUN cd /root/build && sbt compile
EXPOSE 9000
WORKDIR /root/build
CMD sbt compile runQuadtree Animations with Matplotlib
Mon Feb 08 2021
This post will extend my last post on image quadtrees to create an animation that varies the quadtree splitting threshold. Like all recursively dividing algorithms, as you relax the splitting parameter, more partitions get generated. Although this principle makes intuitive sense, seeing animation tells a fuller story.
This post will be using the matplotlib’s animation functionality and the quadtree code I wrote in my previous post. The following code snippet illustrates a simple animation using matplolib:
import numpy as np
from matplotlib import pyplot as plt
from matplotlib.animation import FuncAnimation
fig = plt.figure()
ax = plt.axes(xlim=(0, 4), ylim=(-2, 2))
line, = ax.plot([], [], lw=3)
def init():
line.set_data([], [])
return line,
def animate(i):
x = np.linspace(0, 4, 1000)
y = np.sin(2 * np.pi * (x - 0.01 * i))
line.set_data(x, y)
return line,
anim = FuncAnimation(fig, animate, init_func=init,
frames=200, interval=20, blit=True)
anim.save('Wave.gif')

2020 in Review
Thu Dec 31 2020
2020; this year will likely live in infamy due to covid. Reflecting on this year compared to 2019 is very solemn. Not necessarily because I didn’t accomplish anything; I completed more this year than in 2019. But, 2020 lacks so much travel and in-person events that frequently serve as the milestones for my year.
In my 2019 post, I reflect on all the trips that I took, the hackathons I attended, and the places I gave presentations. However, this year I feel like I can sum up everything I did in a single sentence. I graduated from RIT after taking two consecutive semesters of 18 credit hours, I presented my first published paper at a virtual conference, and I started a full-time job as a software engineer.

Segmenting Images With Quadtrees
Sat Dec 19 2020
Alright, this post is long overdue; today, we are using quadtrees to partition images. I wrote this code before writing the post on generic quad trees. However, I haven’t had time to turn it into a blog post until now. Let’s dive right into this post where I use a custom quadtree implementation and OpenCV to partition images.
But first, why might you want to use quadtrees on an image? In the last post on quadtrees, we discussed how quadtrees get used for efficient spatial search. That blog post covered point quadtrees where every element in the quadtree got represented as a single fixed point. With images, each node in the quadtree represents a region of the image. We can generate our quadtree in a similar fashion where instead of dividing based on how many points are in the region, we can divide based on the contrast in the cell. The end goal is to create partitions that minimize the contrast contained within each node/cell. By doing so, we can compress our image while preserving essential details.
Implementing a Quadtree in Python
Sat Oct 10 2020
This blog post is the first part of a multi-post series on using quadtrees in Python. This post goes over quadtrees’ basics and how you can implement a basic point quadtree in Python. Future posts aim to apply quadtrees in image segmentation and analysis.
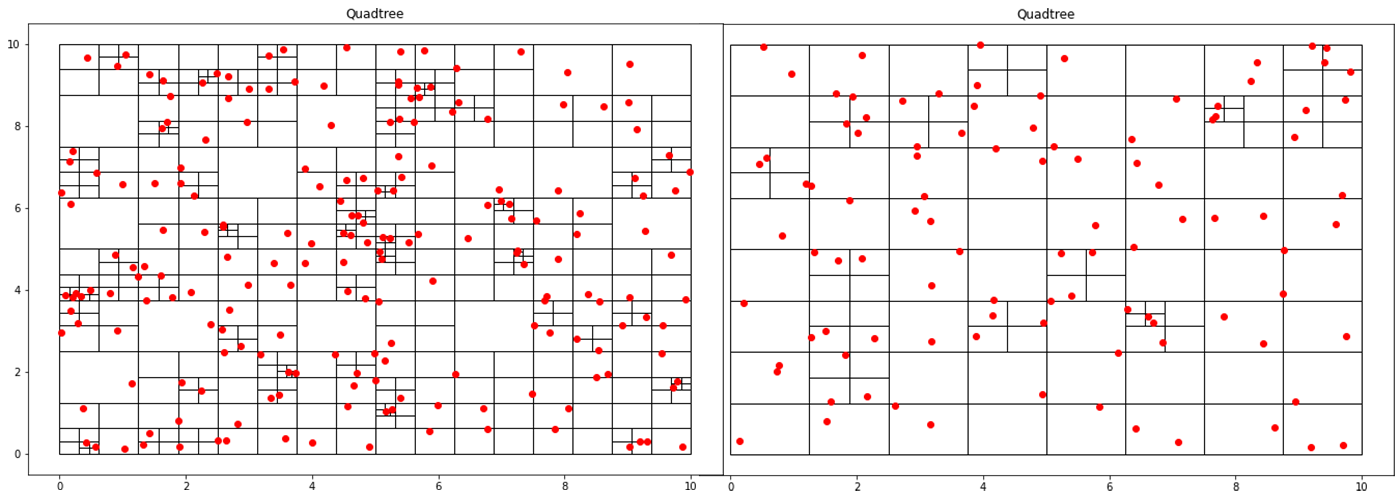
A quadtree is a data structure where each node has exactly four children. This property makes it particularly suitable for spatial searching. Quadtrees are generalized as “k-d/k-dimensional” trees when you have more than 4 divisions at each node. In a point-quadtree, leaf nodes are a single unit of spatial information. A quadtree is constructed by continuously dividing each node until each leaf node only has a single node inside of it. However, this partitioning can be modified so that each leaf node contains no more than K elements or that each cell can be at a maximum X large. This stopping criterion is similar to that of the stopping criteria when creating a decision tree.
Recent Posts
My Wall Mounted Raspberry Pi HomelabThe Data Spotify Collected On Me Over Ten Years
Visualizing Fitbit GPS Data
Running a Minecraft Server With Docker
DIY Video Hosting Server
Running Scala Code in Docker
Quadtree Animations with Matplotlib
2020 in Review
Segmenting Images With Quadtrees
Implementing a Quadtree in Python