CSCI 344 Final Review
Fri Dec 13 2019
A quick review for CSCI-344 (Programming Language Concepts)
1 Ch #1 What are Programming Languages
1.1 Types
1.1.1 Imperative
Most common type of language
- Von Neumann (Fortran, Basic, C)
- Object-oriented (SmallTalk, java)
- Scripting (perl, python, basic)
1.1.2 Declarative
- Functional (Scheme, ML)
- Logical (Prolog)
1.2 Compilation vs Interpretation
Multi Threaded File IO
Thu Jan 31 2019
1 Background
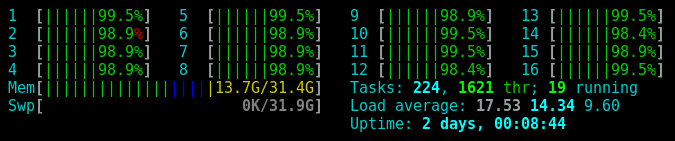
Suppose that you have a large quantity of files that you want your program to ingest. Is it faster to sequentially read each file or, read the files in parallel using multiple threads? Browsing this question online will give varied answers from confused people on discussion threads. Reading resent research papers on multi threaded IO did not quite provide a clear answer my question.
A ton of people argue that multiple threads don’t increase file throughput because at the end of the day a HHD can only read one file at a time. Adding more CPU cores into the mix would actually slow down the file ingest because the HHD would have to take turns between reading fragments of different files. The seek speed of the HHD would heavily degrade the performance.
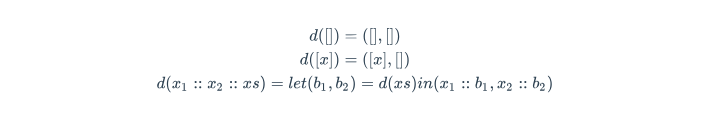
Sorting Algorithms
Sat Dec 15 2018
1 Insertion Sort
Selection sort although not very efficient is often used when the arrays you are sorting are very small. Another benefit of insertion sort is that it is very easy to program. Essentially, this algorithm has a sorted section which slowly grows as it pull in new elements to their sorted position.
1.1 Functional Notation
\[ s([]) = []\\ s(x::xs) = i(x, s(xs)) \]
Knapsack Problem
Tue Dec 11 2018
In this post I will go over how you can frame a question in terms of recursion and then slowly massage the question into a dynamic programming question.
1 Problem Description
The knapsack problem is a famous optimization problem in computer science. Given a set of items, a thief has to determine which items he should steal to maximize his total profits. The thief knows the maximum capacity of his knapsack and the weights and values of all the items.

CS Theory Exam 2 Review
Tue Nov 06 2018
This a very high level review post that I am making for myself and other people reviewing CS Theory. If you want to lean more about content in this blog post I recommend cracking open a text book– I know, gross. This hastily thrown together post will cover how to solve typical problems relating to topics covered by my second CS Theory exam.
1 Myhill-Nerode Theorem
1.1 Definition
L is regular if and only if it has a finite index. The index is the maximum number of elements that are pairwise distinguishable. Two strings are said to be pairwise distinguishable if you can append something to both of the strings and it makes one string accepted by the language and the other string rejected. The size of an index set X equals the number of equivalence classes it has and the minimum number of states required to represent it using a DFA. Each element in the language is accepted by only one equivalence class.
1.2 Problem Approach
Recent Posts
Server Monitoring and Restart Using a Raspberry PiMy Wall Mounted Raspberry Pi Homelab
The Data Spotify Collected On Me Over Ten Years
Visualizing Fitbit GPS Data
Running a Minecraft Server With Docker
DIY Video Hosting Server
Running Scala Code in Docker
Quadtree Animations with Matplotlib
2020 in Review
Segmenting Images With Quadtrees