CSCI 331 Review 1
Sat Sep 28 2019
CSCI-331 Intro to Artificial Intelligence exam 1 review.
1 Chapter 1 What is AI
1.1 Thinking vs Acting
1.2 Rational Vs. Human like
Acting rational is doing the right thing given what you know.
Thinking rationality: - Law of though approach – thinking is all logic driven - Neuroscience – how brains process information - Cognitive Science – information-processing psychology prevailing orthodoxy of hehaviorism
2 Chapter 2 Intelligent Agents
An agent is anything that can view environment through sensors and act with actuators. A rational agent is one that does the right thing.
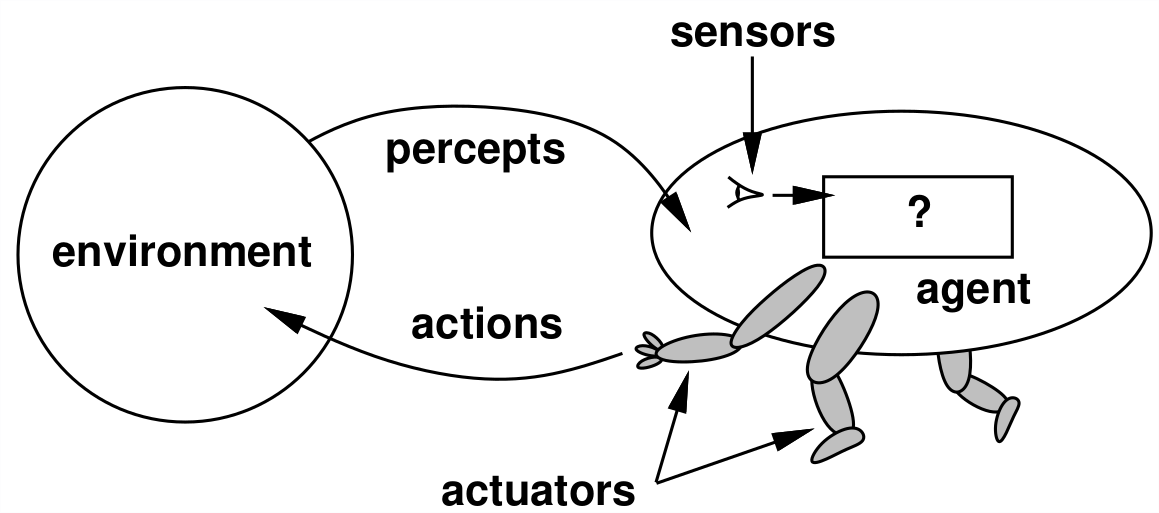
2.1 PEAS
PEAS is an acronym for defining a task environment
2.1.1 Performance Measure
Measure of how well agent is performing.
Ex: safe, fast, legal, profits, time, etc.
2.1.2 Environment
Place in which the agent is acting.
Ex: Roads, pedestrians, online, etc.
2.1.3 Actuators
Way in which agent acts.
Ex: steering, signal, jump, walk, turn, etc.
2.1.4 Sensors
Way which the agent can see the environment.
Ex: Cameras, speedometer, GPS, sonar, etc.
2.2 Environment Properties (y/n)
2.2.1 Observable
Full observable if agent has access to complete state of environment at any given time.
Partially observable if agent can only see part of environment.
2.2.2 Deterministic
If the next state of environment is completely determined by current state it is deterministic, otherwise it is stochastic.
2.2.3 Episodic
If agents current actions does not affect the next problem/performance then it is episodic, otherwise it is sequential
2.2.4 Static
If environment changes while agent is deliberating it is dynamic otherwise it is static.
2.2.5 Discrete
If there are a finite number of states in the environment it is discrete otherwise it is continuous.
2.2.6 Single-Agent
Only one agent in environment like solving a crossword puzzle. A game of chess would be **multi-agent.
2.3 Agent Types
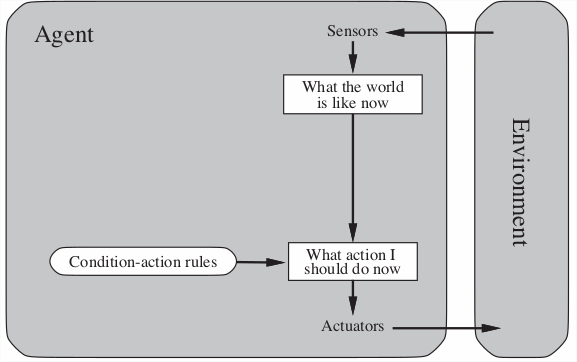
2.3.1 Simple Reflex
Simply responds to a given input based on a action rule set.
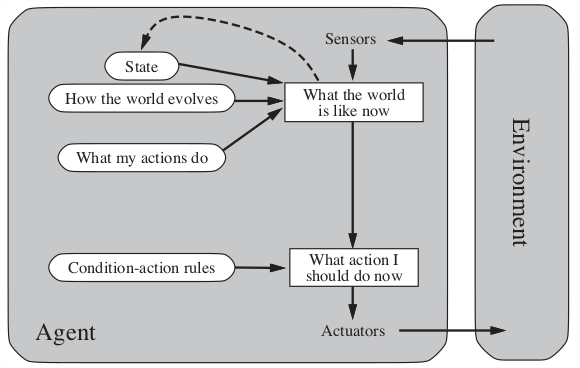
2.3.2 Reflex with state
Understands to some extend how the world evolves.
2.3.3 Goal-based
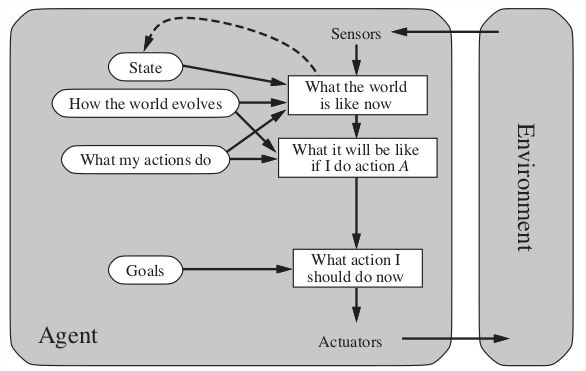
2.3.4 Utility-based
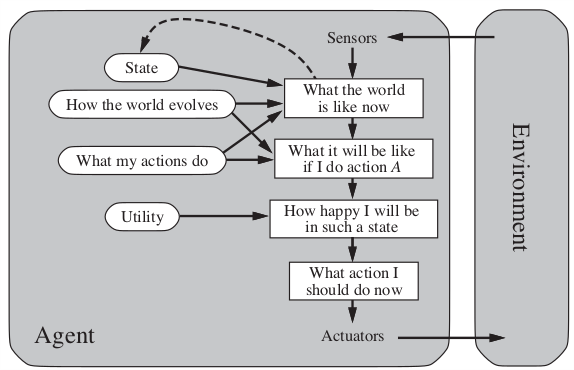
2.3.5 Learning
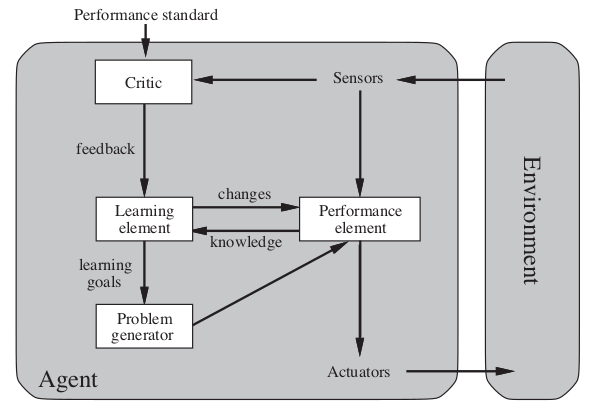
3 Chapter 3 Problem Solving Agents
3.1 Problem Formulation
Process of deciding what actions and states to consider, given a goal.
3.1.1 Initial State
The state that the agent starts in.
3.1.2 Successor Function
A description of the actions available to the agent.
3.1.3 Goal Test
Determines whether a given state is the goal.
3.1.4 Path Cost (Additive)
A function that assigns a numerical cost to each path. The step cost is the number of actions required.
3.2 Problem Types
3.2.1 Deterministic, fully observable => single-state problem
Agent knows exactly which state it will be in; solution is a sequence.
3.2.2 Non-observable => conformant problem
Agent may have no idea where it is; solution (if any) is a sequence
3.2.3 Non-deterministic and/or partially observable => Contingency problem
- Percepts provide new information about current state
- solution is a contingent plan or a policy
- often interleave search, execution
3.2.4 Unknown state space => exploration problem
Exploration problem
4 Chapter 3 Graph and tree search for single-state problems
4.1 Uniformed
AKA blind search. All they can do is generate successors and distinguish a goal state from a non-goal state; they have no knowledge of what paths are more likely to bring them to a solution.

4.1.1 Breadth-first
General graph-search algo where shallowest unexpanded node is chosen first for expansion. This is implemented by using a FIFO queue for the frontier. The solution will be ideal if the path cost between each node is equal.

4.1.2 Depth-first
You expand the deepest unexpanded node first. Implementation: the fringe is a LIFO queue.
4.1.2.1 Depth Limited Search
To avoid an infinite search space, depth limited search provides a max depth that the search algo is willing to traverse.

4.1.3 Uniform-cost
Instead of expanding shallowest nodes, uniform-cost search expands the node n with lowest path cost: g(n). Implementation: priority queue ordered by g.

4.2 Informed
Using problem-specific knowledge, applies an informed search strategy which is often more efficient than uninformed strategies.
4.2.1 Greed best-fit
Tries to expand node that is closest to goal. It evaluates each node by the heuristic function:
\[ f(n) = h(n) \]
A common heuristic used is the euclidean distance (straight line distance) to the solution. Note: this search method can be incomplete since it can still get caught in infinite loops if you don’t use a graph search method or implement an max depth.
4.2.2 A*
Regarded as the best best-first search algo. Combines heuristic distance estimate with actual cost.
\[ f(n) = g(n) + h(n) \]
g gives the cost of getting from the start node to the current node.
In order for this to give optimal cost, h must be an admissible heuristic: an heuristic which never overestimates the cost to reach the goal.
Complete?? no
Time?? \(O(b^{d + 1})\) same as breadth first search but usually faster
Space?? \(O(b^{d + 1})\) keeps every node in memory
Optimal?? Only if the heuristic is admissible.
4.3 Evaluation
4.3.1 Branching factor
4.3.2 Depth of least-cost solution
4.3.3 Maximum depth of tree
4.3.4 Completeness
Is the algo guaranteed to fina a solution if there is one.
4.3.5 Optimality
Will the strategy find the optimal solution.
4.3.6 Space complexity
How much memory is required to perform the search.
4.3.7 Time complexity
How long does it take to find the solution.
4.4 Heuristics
A heuristic function h(n) estimates the cost of a solution beginning from the state at node n.
4.4.1 Admissibility
These heuristics can be derived from a relaxed version of a problem. Heuristic must never overestimate the cost to reach the goal.
4.4.2 Dominance
If one heuristic is greater than another for all states n, then it dominates the other. Typically dominating heuristics are better for the search. You can form a new dominating admissible heuristic by taking the max of two other admissible heuristics.
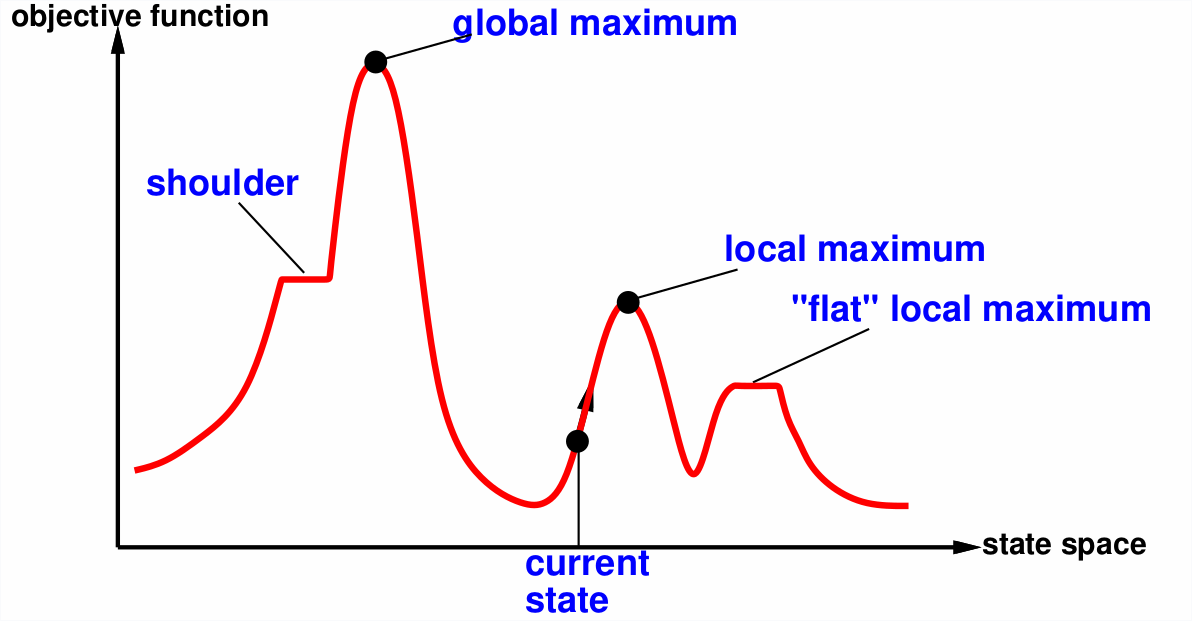
5 Chapter 4 Iterative Improvement
Optimization problem where the path is irrelevant, the goal state is the solution. Rather than searching through all possible solutions, iterative improvement takes the current state and tries to improve it. Since the solution space is super large, it is often not possible to try every possible combination.
5.1 Hill Climbing
Basic algorithm which continually moves in the direction of increasing value.
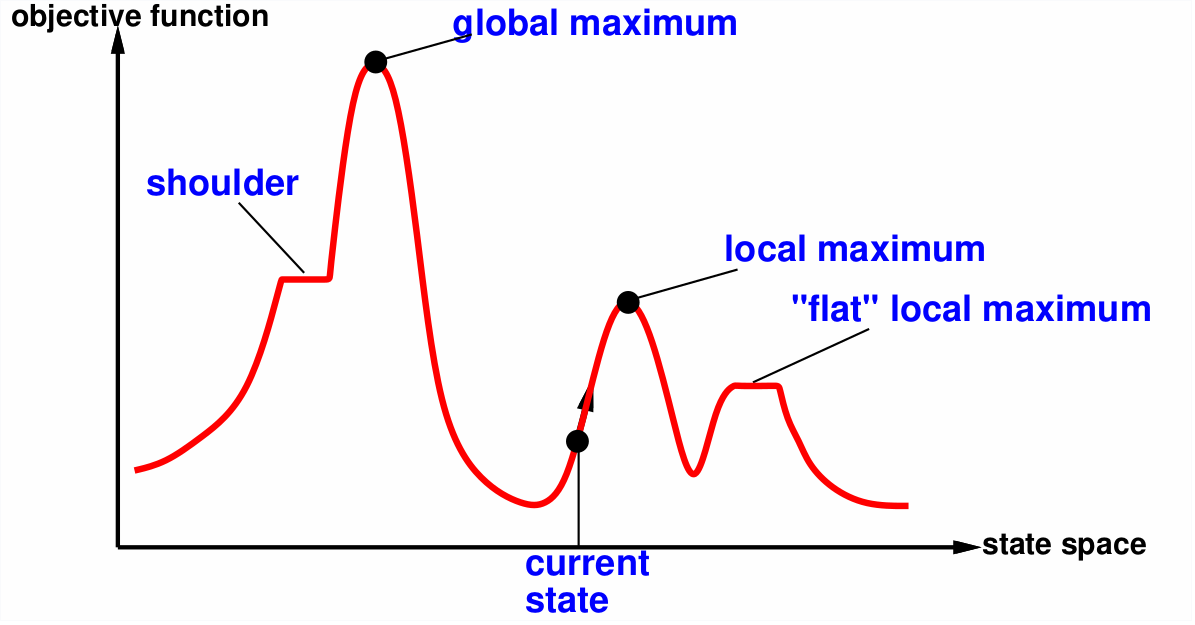
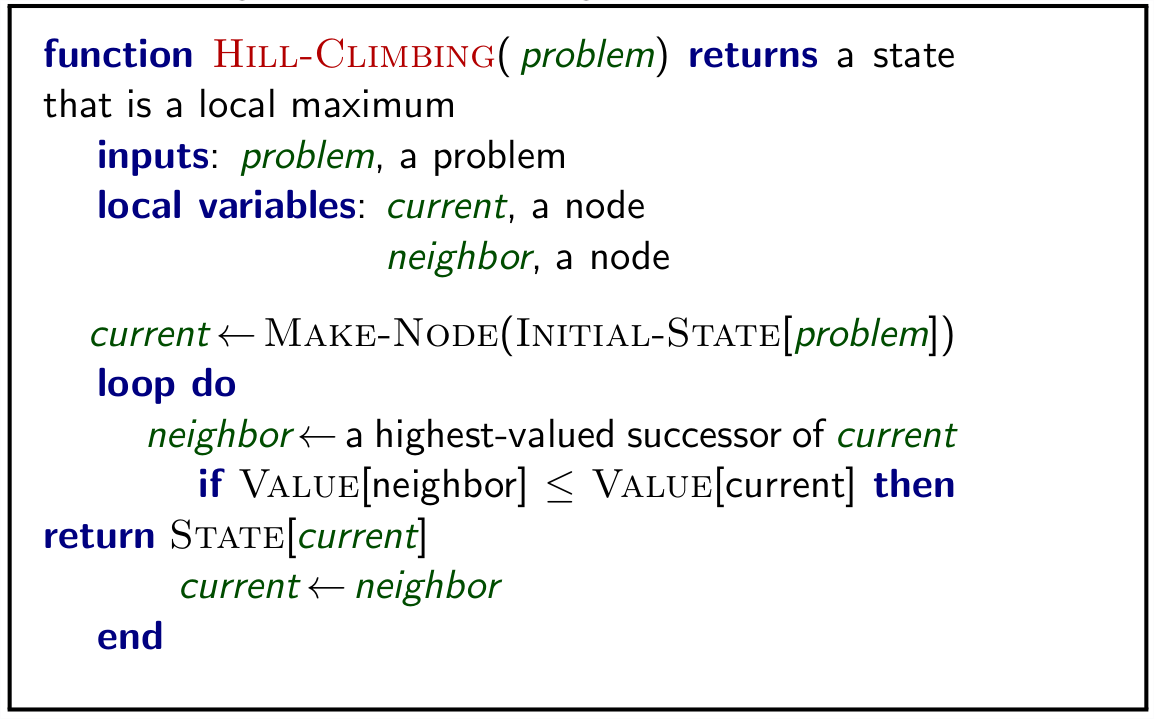
To avoid finding a local maximum several methods can be employed:
- Random-restart hill climbing
- Random sideways move – escapes from shoulders loop on flat maxima.
5.2 Simulated annealing
Idea: escape local maxima by allowing some bad moves but gradually decrease their size and frequency. This is similar to gradient descent. Idea comes from making glass where you start very hot and then slowely cool down the temperature.
5.3 Beam Search
Idea: keep k states instead of 1; choose top k of their successors.
Problem: quite often all k states end up on same local hill. This can somewhat be overcome by randomly choosing k states but, favoring the good ones.
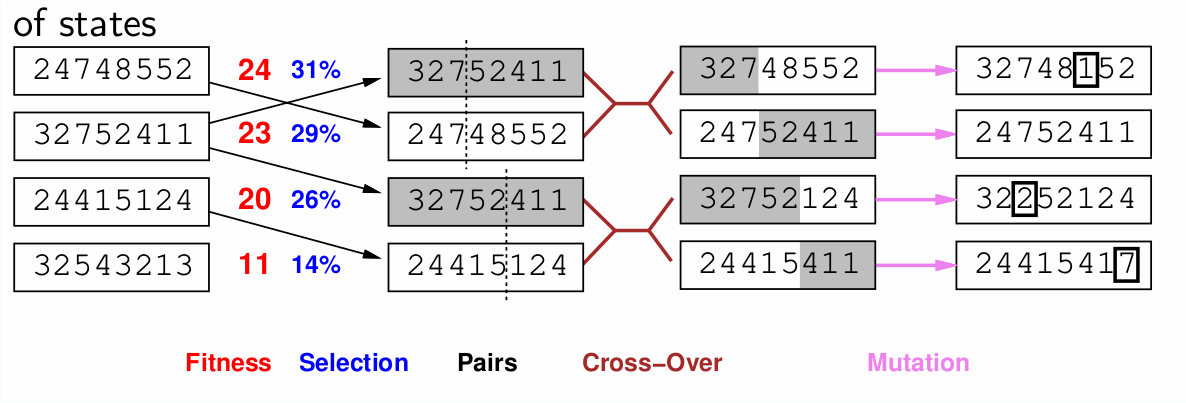
5.4 Genetic Algorithms
Inspired by Charles Darwin’s theory of evolution. The algorithm is an extension of local beam search with cuccessors generated from pairs of individuals rather than a successor function.

6 Chapter 5 Game Theory
6.1 Minimax
Algorithm to determine perfect play for deterministic, perfect information games. Idea: assume opponent is also a rational agent, you choose to make the choice which is the best achievable payoff against the opponents best play.
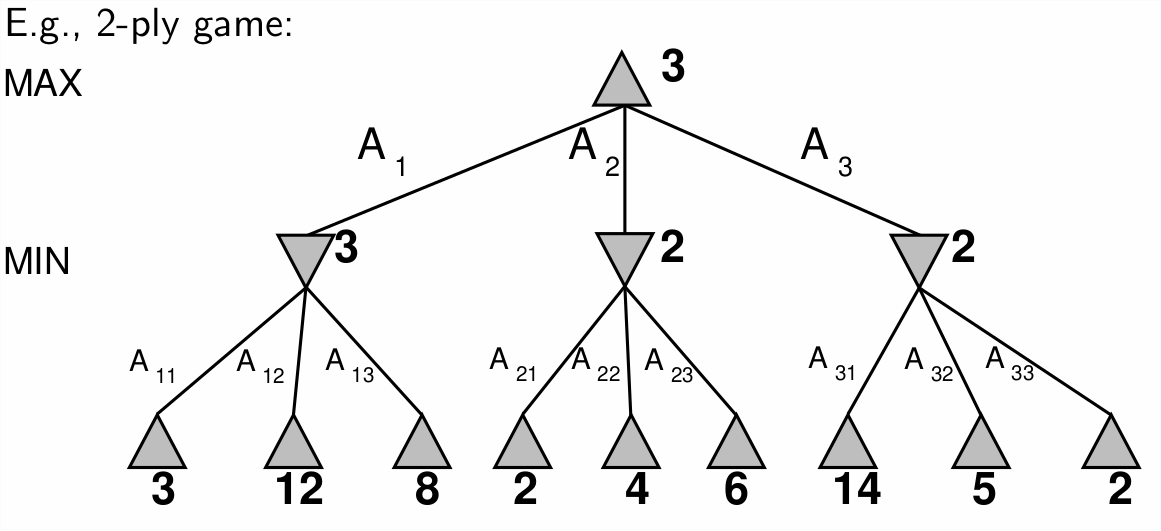

6.1.1 Properties
- complete: yes if tree is finite
- optimal: yes, against an optimal opponent
- Time complexity: \(O(B^m)\)
- Space Complexity: \(O(bm)\) depth-first exploration
This makes a game of chess with a branch factor of 35 and estimated moves around 100 totally infeasible: 35^100!
6.2 α-β pruning
Idea: prune paths which will not yield a better solution that one already found. The pruning does not affect the final result. Good move exploration ordering will improve the effectiveness of pruning. With perfect ordering, time complexity is: \(O^{\frac{m}{2}}\). This doubles our solvable depth, but, still infeasible for chess.
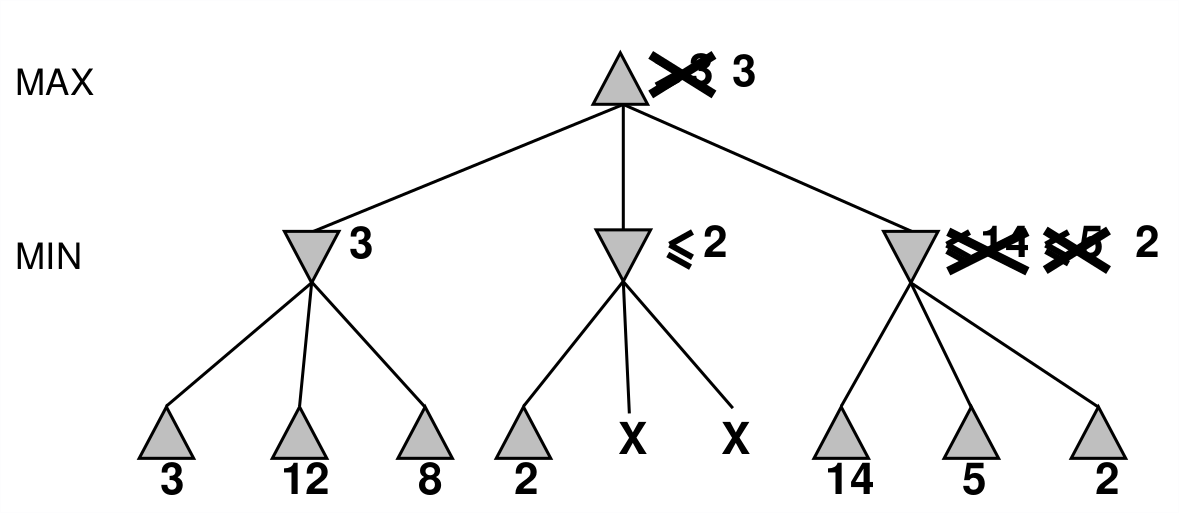

6.3 Resource limits
Due to constraint, we typically use the Cutoff-test rather than the terminal-test. The terminal test requires us to explore all nodes in the mini-max search. The cutoff test branches out to a certain depth and then applies a evaluation function to determine the desirability of a position.
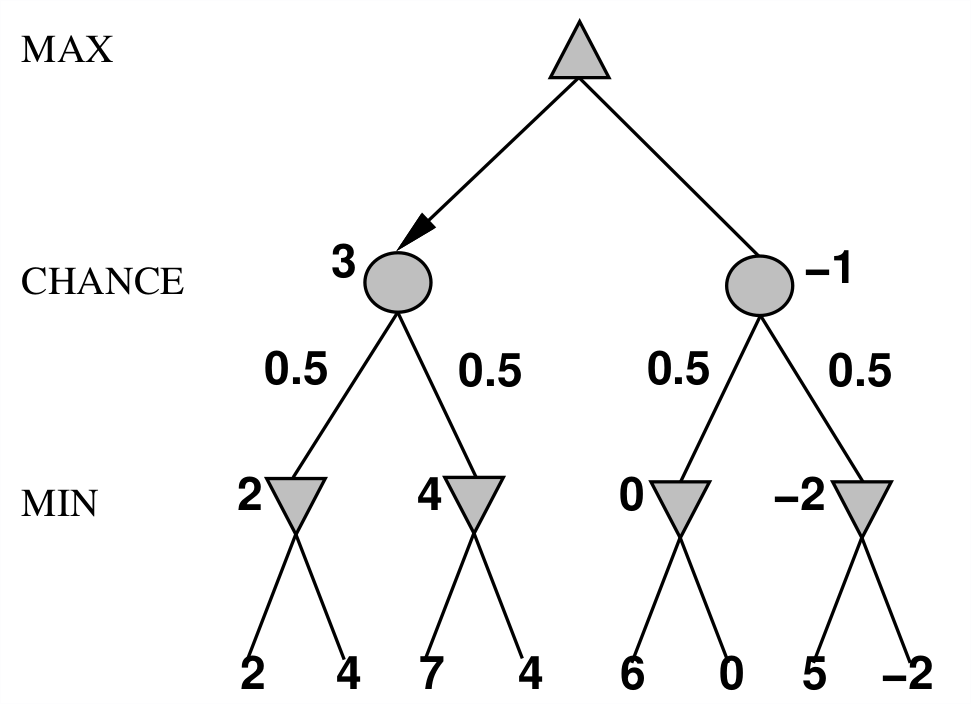
6.4 Randomness/ Nondeterministic games
Often times games involve chance such as a coin flip or a dice roll. You can modify the mini-max tree to branch with each probability and take the average of evaluating each branch.
Recent Posts
My Wall Mounted Raspberry Pi HomelabThe Data Spotify Collected On Me Over Ten Years
Visualizing Fitbit GPS Data
Running a Minecraft Server With Docker
DIY Video Hosting Server
Running Scala Code in Docker
Quadtree Animations with Matplotlib
2020 in Review
Segmenting Images With Quadtrees
Implementing a Quadtree in Python